架構設計技術之分布式數據存儲 數據處理與存儲支持服務解析
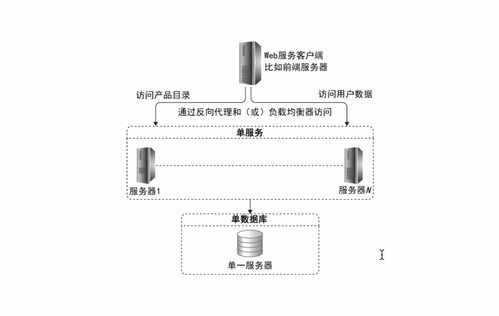
在當今數據爆炸的時代,傳統的集中式數據存儲方式已難以滿足海量數據處理、高并發訪問和系統高可用性的需求。分布式數據存儲作為現代架構設計的核心技術,通過將數據分散存儲在多臺獨立的服務器上,并結合高效的數據處理與存儲支持服務,為構建可擴展、高可靠、高性能的應用系統提供了堅實基礎。
一、分布式數據存儲的核心價值與挑戰
分布式數據存儲的核心價值在于其可擴展性、高可用性和容錯性。通過水平擴展,系統可以近乎線性地提升存儲容量和處理能力;通過數據多副本機制,保障了在部分節點失效時服務的連續性。這也帶來了數據一致性、分區容錯性、跨節點事務管理以及系統復雜度顯著增加等挑戰,這正是CAP定理、BASE理論等分布式理論需要解決的核心問題。
二、關鍵數據處理模式與架構
數據處理是分布式存儲系統的靈魂,主要分為批處理與流處理兩大范式。
- 批處理:針對靜態的大規模數據集進行操作,如Hadoop MapReduce、Spark等框架,適用于歷史數據分析、報表生成等場景。其架構通常遵循“分而治之”思想,將任務拆分到多個節點并行計算后匯總。
- 流處理:對連續不斷產生的數據流進行實時或近實時處理,如Flink、Storm、Kafka Streams。其架構強調低延遲和狀態管理,能夠實現實時監控、即時推薦等業務需求。
三、存儲支持服務:數據管理的基石
分布式存儲不僅僅是數據的存放地,更依賴一系列支持服務來實現高效、可靠的數據管理。
- 元數據管理:負責記錄數據塊的分布位置、副本信息、訪問權限等,是系統尋址和調度的中樞。例如,HDFS的NameNode、Ceph的Monitor集群。
- 一致性協議與協調服務:確保在分布式環境下各節點狀態協同一致。Paxos、Raft等共識算法是構建強一致性存儲(如etcd、ZooKeeper)的核心,后者常作為分布式系統的配置中心、命名服務和分布式鎖的實現基礎。
- 數據分區與路由:通過一致性哈希、范圍分區等策略,將數據均勻分布到集群節點,并確保客戶端能精準定位數據所在。這是實現負載均衡和橫向擴展的關鍵。
- 副本管理與故障恢復:自動管理數據的多副本復制、放置策略(如機架感知),并在節點故障時觸發副本重新復制與數據重平衡,保障數據的持久性與可用性。
- 分布式事務與鎖服務:對于需要跨節點、跨分片保證ACID特性的場景,如分布式數據庫,需要2PC、3PC、TCC等方案或全局時鐘(如Spanner的TrueTime)來支持。
四、典型技術棧與選型考量
實踐中,技術選型需緊密結合業務場景:
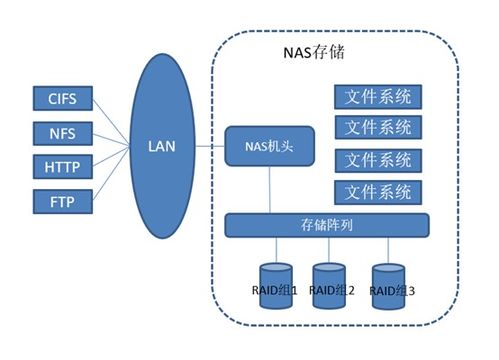
- 對象/塊/文件存儲:如Ceph、MinIO提供兼容S3的對象存儲;HDFS適合大數據批處理場景。
- 分布式數據庫:Cassandra、HBase適合海量KV存儲;TiDB、CockroachDB提供NewSQL的分布式關系型能力;MongoDB提供文檔模型的分布式支持。
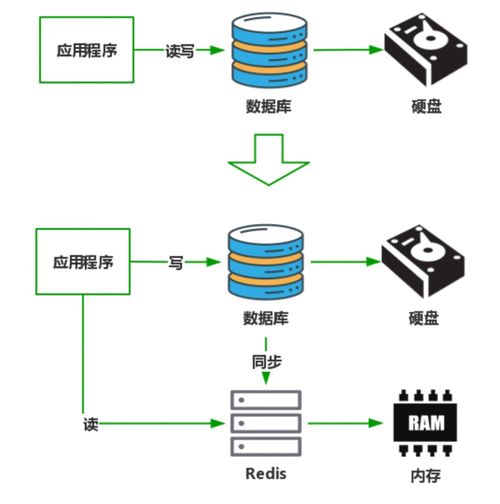
- 緩存與內存網格:如Redis Cluster、Ignite,提供高性能的分布式緩存與內存計算。
選型時需權衡數據模型、一致性要求、讀寫模式、延遲敏感性及運維成本。
五、未來趨勢與展望
隨著云原生和算力網絡的發展,分布式數據存儲正呈現以下趨勢:存儲與計算進一步分離,以實現更極致的彈性;智能化的數據放置與流動策略,以優化性能和成本;Serverless數據庫與存算一體架構的探索,旨在簡化開發運維;以及對異構數據(圖、時序、向量)的統一存儲與處理支持,賦能AI與物聯網應用。
分布式數據存儲及其配套的數據處理與存儲支持服務,構成了現代大規模應用的數據基石。深入理解其核心原理、技術組件與權衡藝術,是每一位架構師設計出健壯、高效、適應未來發展的系統所必備的技能。成功的架構永遠是業務需求、技術可行性與運維復雜度之間的精巧平衡。
如若轉載,請注明出處:http://m.findray.cn/product/56.html
更新時間:2026-04-08 23:24:36